
原文作者:Tal Sheffer | 来源:qodo.ai blog
最近我们看到了不少很酷的生成式 AI 编程演示,有些甚至会让你觉得,仿佛已经有一个勤奋的 AI Agent 正在疯狂承接 Upwork 上的项目。话虽如此,这些“Upwork 大神”式的 AI,在面对拥有数千个代码仓库、数百万行(大多是遗留)代码的真实企业级代码库时,还是完全不够看的。对于希望采用生成式 AI 的企业开发者来说,上下文感知能力是成功的关键。这正是 Retrieval Augmented Generation (RAG) 技术的用武之地,然而,要将 RAG 落地到大规模代码库中也面临着独特的挑战。
在企业级层面使用 RAG 的首要障碍之一是 scalability(可扩展性)。RAG 模型必须处理海量数据,并应对跨不同仓库的架构复杂性,这使得实现上下文理解变得困难。在这篇博客中,我将分享 qodo(前身为 Codium)如何通过 RAG 方法,在构建以代码质量和完整性为先的生成式 AI 编程平台的同时,弥合 context windows 有限的 LLM 与庞大复杂代码库之间的差距。
将 RAG 应用于大规模代码仓库
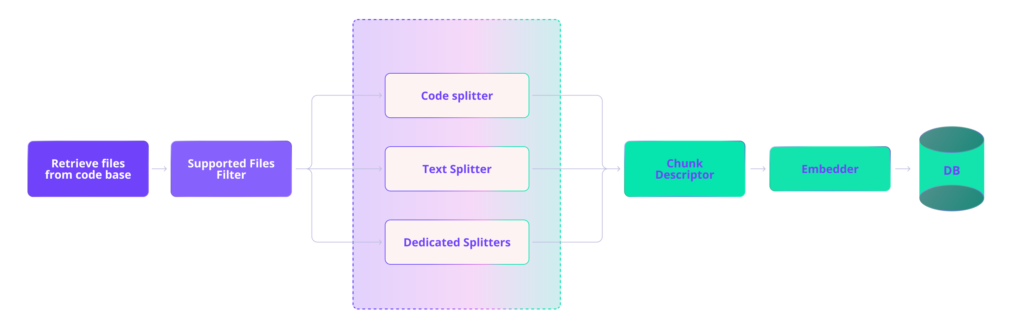
RAG 大致可以分为两部分:索引知识库(在我们的例子中是代码库)和检索。对于不断变化的生产环境代码库,索引并不是一次性或周期性的工作。我们需要一个强大的 pipeline 来持续维护最新的索引。下图展示了我们的 ingest pipeline:文件被路由到适当的 splitter 进行 chunking,chunk 会被加上自然语言描述进行增强,然后为每个 chunk 生成 vector embeddings,最后存储在 vector DB 中。
Chunking
对于自然语言文本,Chunking 相对简单——段落(和句子)提供了明显的边界点,可以创建语义上有意义的片段。然而,朴素的 chunking 方法很难准确地划分有意义的代码片段,导致边界定义问题以及包含无关或不完整的信息。我们发现,向 LLM 提供无效或不完整的代码片段实际上会损害性能并增加幻觉,而不是提供帮助。
Sweep AI 团队去年发布了一篇很棒的博文[译者注:原文链接已失效,此处为修正后的正确链接,指向 Sweep AI 团队在 GitHub 上关于代码分块方案的技术博客。],详细介绍了他们的代码 chunking 策略。他们开源了使用 concrete syntax tree (CST) parser 来创建连贯 chunk 的方法,�该算法后来被 LlamaIndex 采用。
这是我们的起点,但我们在他们的方法中遇到了一些问题:
-
尽管有所改进,但 chunk 仍然不总是完整的,有时会丢失关键的 context,如 import 语句或类定义。
-
对可嵌入 chunk 大小的硬性限制并不总是允许捕获较大代码结构的完整 context。
-
该方法没有考虑到企业级代码库的独特挑战。
为了解决这些问题,我们开发了几种策略:
智能 Chunking 策略
Sweep AI 使用 static analysis(静态分析)实现了 chunking,这是对以前方法的巨大改进。但在当前节点超过 token 限制并开始将其子节点拆分为 chunk 而不考虑 context 的情况下,他们的方法并不是最优的。这可能导致在方法或 if 语句中间断开 chunk(例如,‘if’ 在一个 chunk 中,而 ‘else’ 在另一个中)。
为了缓解这个问题,我们使用特定于语言的 static analysis 将节点递归地划分为更小的 chunk,并执行追溯处理以重新添加任何被移除的关键 context。这使我们能够创建尊重代码结构的 chunk,将相关元素保持在一起。
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
def modulus(self):
return math.sqrt(self.real**2 + self.imag**2)
def add(self, other):
return ComplexNumber(self.real + other.real, self.imag + other.imag)
def multiply(self, other):
new_real = self.real * other.real - self.imag * other.imag
new_imag = self.real * other.imag + self.imag * other.real
return ComplexNumber(new_real, new_imag)
def __str__(self):
return format_complex(self.real, self.imag)
Naive chunking:
def __str__(self):
return format_complex(self.real, self.imag)
[译者注:Naive chunking 只保留了方法本身,但丢失了其所属的类定义(ComplexNumber)、构造函数(init)以及依赖的 import 语句(format_complex),导致上下文不完整。]
Our chunking:
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
# …
def __str__(self):
return format_complex(self.real, self.imag)
我们的 chunker 将关键 context 与类方法保持在一起,包括任何相关的 import 以及类定义和 init 方法,确保 AI 模型拥有理解和处理此代码所需的所有信息。
在 Chunk 中维护 Context
我们发现,embedding 较小的 chunk 通常会带来更好的性能。理想情况下,你希望拥有包含相关 context 的最小可能的 chunk——包含任何无关内容都会稀释 embedding 的语义含义。我们的目标是使 chunk 尽可能小,并将限制设定在 500 个字符左右。大型类或复杂的代码结构通常会超过此限制,导致代码表示不完整或碎片化。
因此,我们开发了一个系统,允许灵活的 chunk 大小,并确保关键 context(如类定义和 import 语句)包含在相关的 chunk 中。
对于一个大型类,我们可能会为单个方法分别创建 embedding 和索引,但在每个方法 chunk 中包含类定义和相关的 import。这样,当检索到特定方法时,AI 模型就拥有了理解和处理该方法所需的完整 context。
不同文件类型的特殊处理
不同的文件类型(例如代码文件、配置文件、文档)需要不同的 chunking 策略来维护其语义结构。
我们为各种文件类型实施了专门的 chunking 策略,特别关注像 OpenAPI/Swagger 规范这样具有复杂、互连结构的文件。
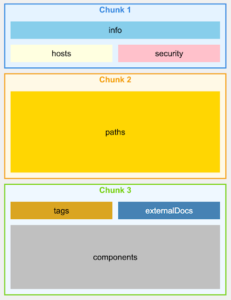
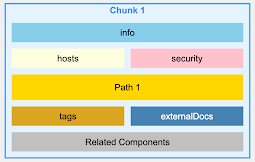
对于 OpenAPI 文件,我们不是按行或字�符进行 chunking,而是按 endpoints 进行 chunking,确保每个 chunk 包含特定 API endpoint 的所有信息,包括其参数、响应和安全定义。
OpenAPI v3.0 – Naive Chunking
OpenAPI v3.0 – Intelligent Chunking
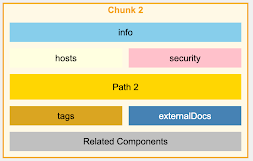
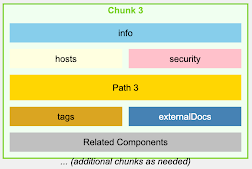
使用自然语言描述增强 Embeddings
代码 embeddings 通常无法捕捉代码的语义含义,特别是对于自然语言查询。
我们使用 LLM 为每个代码 chunk 生成自然语言描述。然后将这些描述与代码一起 embed,从而增强我们针对自然语言查询检索相关代码的能力。
对于前面展示的 map_finish_reason 函数:
# What is this?
## Helper utilities
def map_finish_reason( finish_reason: str,):
# openai supports 5 stop sequences - 'stop', 'length', 'function_call', 'content_filter', 'null'
# anthropic mapping
if finish_reason == "stop_sequence":
return "stop"
# cohere mapping - https://docs.cohere.com/reference/generate
elif finish_reason == "COMPLETE":
return "stop"
elif finish_reason == "MAX_TOKENS": # cohere + vertex ai
return "length"
elif finish_reason == "ERROR_TOXIC":
return "content_filter"
elif ( finish_reason == "ERROR" ): # openai currently doesn't support an 'error' finish reason
return "stop"
# huggingface mapping https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate_stream
elif finish_reason == "eos_token" or finish_reason == "stop_sequence":
return "stop"
elif ( finish_reason == "FINISH_REASON_UNSPECIFIED"
or finish_reason == "STOP" ): # vertex ai - got from running `print(dir(response_obj.candidates[0].finish_reason))`: ['FINISH_REASON_UNSPECIFIED', 'MAX_TOKENS', 'OTHER', 'RECITATION', 'SAFETY', 'STOP',]
return "stop"
elif finish_reason == "SAFETY" or finish_reason == "RECITATION": # vertex ai
return "content_filter"
elif finish_reason == "STOP": # vertex ai
return "stop"
elif finish_reason == "end_turn" or finish_reason == "stop_sequence": # anthropic
return "stop"
elif finish_reason == "max_tokens": # anthropic
return "length"
elif finish_reason == "tool_use": # anthropic
return "tool_calls"
elif finish_reason == "content_filtered":
return "content_filter"
return finish_reason
我们可能会生成如下描述:
“Python function that standardizes finish reasons from various AI platforms, mapping platform-specific reasons to common terms like ‘stop’, ‘length’, and ‘content_filter’.”
(Python 函数,用于标准化来自各种 AI 平台的完成原因,将特定于平台的原因映射到通用术语,如 ‘stop’、‘length’ 和 ‘content_filter’。)
然后将此描述与代码一起 embed,从而改进对诸如“how to normalize AI completion statuses across different platforms”等查询的检索。这种方法旨在解决当前 embedding 模型中的差距,这些模型不是面向代码的,并且缺乏自然语言和代码之间的有效转换。
高级检索和排序
简单的向量相似度搜索通常会检索到不相关或脱离 context 的代码片段,特别是在拥有数百万索引 chunk 的大型多样化代码库中。
我们实施了两阶段检索过程。首先,我们从 vector store 中执行初始检索。然后,我们使用 LLM 根据结果与特定任务或查询的相关性对结果进行过滤和排序。
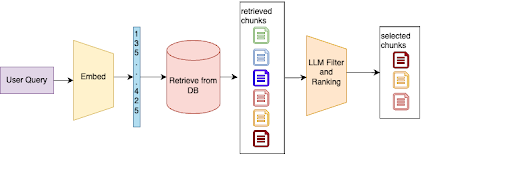
如果开发者查询“how to handle API rate limiting”,我们的系统可能会首先检索几个与 API 调用和错误处理相关的代码片段。然后,LLM 会在查询的 context 中分析这些片段,将那些专门处理速率限制逻辑的片段排在前面,并丢弃不相关的结果。
为企业仓库扩展 RAG
随着仓库数量增长到数千个,如果在每次查询时都跨所有仓库进行搜索,检索会变得嘈杂且效率低下。
我们正在开发 repo 级别的过滤策略,以便在深入研究单个代码 chunk 之前缩小搜索空间。这包括“golden repos”的概念——允许组织指定符合最佳实践并包含组织良好代码的特定仓库。
对于关于特定 microservice(微服务)架构模式的查询,我们的系统可能会首先根据 metadata 和高级内容分析识别出最有可能包含相关信息的 5-10 个仓库。然后,它会在这些仓库中执行详细的代码搜索,从而显著减少噪音并提高相关性。
RAG 基准测试和评估
由于缺乏标准化的 benchmarks,评估代码 RAG 系统的性能具有挑战性。
我们开发了一种多方面的评估方法,结合了自动化指标和来自企业客户的真实使用数据。
我们结合使用相关性评分(开发者实际使用检索到的代码片段的频率)、准确性指标(针对代码补全任务)和效率测量(响应时间、资源使用)。我们还与企业客户密切合作,收集反馈和真实的性能数据。
结论
为海量企业代码库实施 RAG 带来了超出典型 RAG 应用的独特挑战。通过�专注于智能 chunking、增强的 embeddings、高级检索技术和可扩展架构,我们开发了一个能够有效导航和利用企业级代码库中蕴含的巨大知识的系统。
随着我们继续完善我们的方法,我们对 RAG 彻底改变开发者与大型复杂代码库交互方式的潜力感到兴奋。我们相信,这些技术不仅会提高生产力,还会提高大型组织内的代码质量和一致性。